SELECT TIME_TO_SEC('05:15:40');
Sample Output:
mysql> SELECT TIME_TO_SEC('05:15:40');
+-------------------------+
| TIME_TO_SEC('05:15:40') |
+-------------------------+
| 18940 |
+-------------------------+
1 row in set (0.02 sec)
mysql> SELECT SEC_TO_TIME(18940);
+-------------------------+
| SEC_TO_TIME(18940) |
+-------------------------+
| 05:15:40 |
+-------------------------+
1 row in set (0.02 sec)
참고: https://www.w3resource.com/mysql/date-and-time-functions/mysql-time_to_sec-function.php
'Database > Mysql, MariaDB' 카테고리의 다른 글
| MariaDB 인증(Authentication) 방식에 대한 변경 및 주의 사항 (1) | 2024.03.23 |
|---|---|
| mariadb, mysqlDB root password 초기화 (0) | 2024.03.23 |
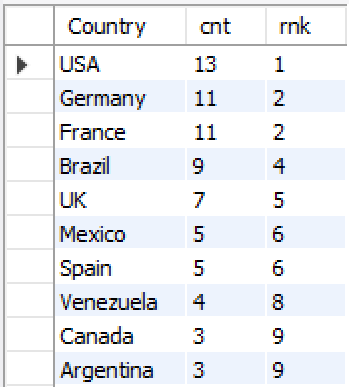
| [Mysql] count over PARTITION BY (0) | 2021.04.14 |
| (1292): Truncated incorrect DOUBLE value (0) | 2020.11.19 |
| [Mysql] DUPLICATE KEY UPDATE for multiple rows insert in single query (0) | 2020.11.18 |